These notes are primarily from a talk that the author, Thomas Ma, gave to us at the University of Toronto’s Computational Social Science Lab
Rating Systems as Levers of Fairness
- Most platforms use a very simple rating system—just the average of user reviews
- This treats every new review as equally informative, regardless of how early or noisy it is
- It means early luck (good or bad) can disproportionately affect a product’s future
- Their central question: Can we design rating systems that are more fair to producers without ruining the user experience?
- “Fair” here means: producers with the same actual quality shouldn’t have wildly different outcomes just because of random chance
- They call this individual producer fairness
- Their framing: treat the platform as a Bayesian updater
- Every product starts with a system-wide prior belief (like: “on average, products are 4 stars”)
- As reviews come in, the system updates its belief using Bayes’ Rule
- The more reviews it has, the more it trusts the data and moves away from the prior
- The key design lever is prior strength (called η, or ada in the talk Thomas gave us)
- High η → stronger prior → early reviews have less impact
- System waits longer before deciding a product is “good” or “bad”
- Reduces early randomness but slows learning
- Low η → weaker prior → system listens to early reviews more
- Faster to identify great products, but riskier—more randomness in who succeeds
- High η → stronger prior → early reviews have less impact
The Core Trade-Off: Efficiency vs Fairness
- Efficiency = how good the consumer experience is (are they being shown the best stuff?
- Fairness = how evenly outcomes are distributed across producers with similar quality
- A system that’s too fast to react to early ratings might amplify bad luck
- A system that’s too cautious might treat high-quality and low-quality products the same for too long
- This tension showed up across two models:
- Fixed model: every product gets rated equally often, regardless of past ratings
- Useful for analyzing the trade-off in a clean, controlled setting
- Shows that bias (inefficiency) and variance (unfairness) pull in opposite directions as you adjust η
- Responsive model: more realistic: better-rated products get seen and rated more
- Now, early luck can compound—good first ratings = more exposure = more good ratings
- Without a prior, it becomes a “rich-get-richer” system
- Fixed model: every product gets rated equally often, regardless of past ratings
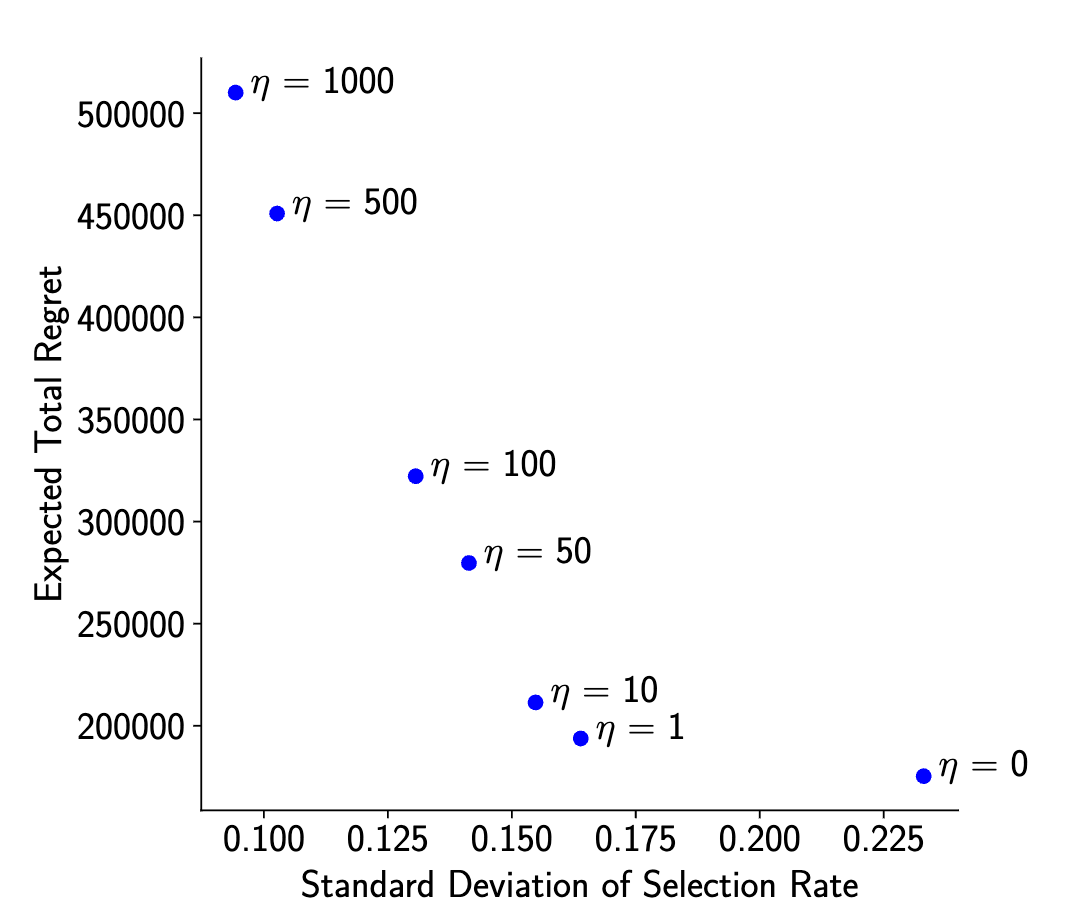
- Charts showed that even slight increases in prior strength (e.g., η = 1 or 10) make the system much fairer
- In some datasets, moving from η = 0 to η = 1 reduced unfairness by 30% with only 10% loss in match quality
- The graphs of regret vs variance all showed clear Pareto curves—no free lunch, but clear trade-offs
The Role of Prior Strength (η)
- Thomas emphasized the design choice of setting the prior, which is usually invisible to users
- Many platforms unknowingly set η = 0 (sample mean) by default
- Stronger priors don’t change what a product can become, just how fast that decision is made
- “You need more evidence before we believe the hype (or the hate)”
- Figures like the violin plots made this visual:
- At η = 0: high-quality products either explode or get buried—huge variance
- At η = 1000: all products kind of float at the same level for a long time—very stable, but not very efficient
- η = 10 or 50 seemed to strike a better balance
- Another key figure: selection rates based on how many of the first 4 reviews were positive
- Even among truly high-quality products, early reviews made a huge difference unless the prior was strong
- With low η: one bad review and your fate is sealed
- With high η: the system waits before reacting—no snowball
Design Implications and Takeaways
- The main argument: platforms should explicitly decide how much they want to prioritize fairness
- The prior strength is not just a technical detail but a value decision
- If you care about giving new producers a fair shot, you shouldn’t be using the sample mean
- And importantly: you don’t need to give up much efficiency to gain fairness
- A small shift in η can go a long way
- Designers should think of rating systems as policy levels rather than just math
- A more stable system might reduce churn, help good producers stay in the market, and increase long-term platform quality