Introduction
- Machine learning models have surpassed human decision-making in many domains
- This has led to people building AI models that interact with humans
- The goal is to interact and collaborate with humans
- While most current AI models focus on characterizing human behavior as a species, real human-AI collaboration will require models that are specialized to individual people
- Essentially, developing algorithms that can identify patterns and signatures in decision-making style for specific individuals. This has a few subtasks:
- First, Identifying an individual from their behavioural characteristics
- Helps the AI system coordinate with the individual and adapt their style
- Second, help models isolate the distinguishing features of individual styles
- Since AI is already superhuman in many fields, understanding human decisions can help the model guide a human to improve their own choices
- Third, applying the same algorithms to multiple different people would shed light on decision-making across all humans
- First, Identifying an individual from their behavioural characteristics
- This entire process is coined as behavioural stylometry*, where the goal is to identify a decision-maker just from their decisions. In the paper, they pursue this through chess (identifying players from their moves alone)
- They adopt a transformer-based approach that is used in traditional stylometry of speech verification and extend these models to the complex data found in chess
- The model is able to create embeddings of players and games, revealing a structure of human style in chess. Players who are stylistically similar are clustered together in the space.
Background
- Speaker verification is the binary process of classifying whether a given a certain utterance, the model verifies if it was from the speaker or not. Recent approaches use embeddings in a vector space to distinguish between different voices.
- Stylometry is the overarching task of detecting and analyzing authorial style. For example, de-anonymizing programmers from their code, identifying age and gender from blog posts and distinguishing between machine-generated text and human-generated text.
Methodology
- The model has three main components:
- Extracting features from individual moves (residual blocks)
- Aggregates move-level features to game-level vectors (transformers)
- Aggregates player’s game vectors by calculating their centroid, producing a player vector that represents their style
Move-Level Feature Extraction
- A series of residual blocks
- Input is 34 channel 8x8 chess move representation. A move will have two board positions, one before and after the player’s move.
- First 24 channels encode a specific type of chess piece (6 for each side in one position, and two encoded positions) and the next 10 channels are to encode position metadata (such as repetition, castling rights, active player’s side, etc)
- The output is a 320-dimensional vector that characterizes every move
- Each residual block contains convolutional layers, batch normalization, |ReLU activation functions and squeeze-and-excitation blocks
- Then, global average pooling summarizes the residual block output into a 1x1x320 feature map which is flattened to a 320 dimensional vector
- Hyperparameters were chosen to match Maia: 6 residual blocks with a channel size of 64, and a reduction ratio of 8 for SE blocks
- Input is 34 channel 8x8 chess move representation. A move will have two board positions, one before and after the player’s move.
Game-Level Aggregation
- Constructs a game representation by taking in a sequence of move features from the first component
- Input corresponds to moves played by the target player in a particular game
- Output is a game vector that aggregates information about the move features
- Typically an LSTM is used, but a modified Vision Transformer was used in this paper
- First, input is modified to take a sequence of move features
- Directly average the output vectors of the transformer blocks
- Since the move features are fed into the transformer simultaneously, they retain the ordering of the moves by adding positional encoding to each move feature
- The vision transformer architecture has a learnable 1D position embedding in the input sequence
- Each 320-dimensional input vector is projected to 1024 dimensions, and positional encoding is appended to each before they are fed to the transformer encoder
- The encoder has 12 transformer blocks, each with one attention layer followed by a feed-forward layer, with layer normalization applied before each.
- There are 8 attention heads, each with 64 dimensions, in each attention layer
- The feed-forward layer uses MLP with two layers to project the 1024-dimensional vector to 2048 dimensions, where GELU activation is applied. Another layer projects it back to 1024 dimensions
- Each output vector corresponds to an input move feature, and these vectors are averaged to get a single vector of 1024 dimensions, which is projected with MLP into the final embedding space.
- This 512-dimension embedding vector encodes the decisions made by the player in the game. At inference time, the player vector is obtained by simply averaging all the game vectors that belong to the player
- The model is trained with a batch size of 800 games, where it is fed 20 games of 40 different players
Evaluation
Data
-
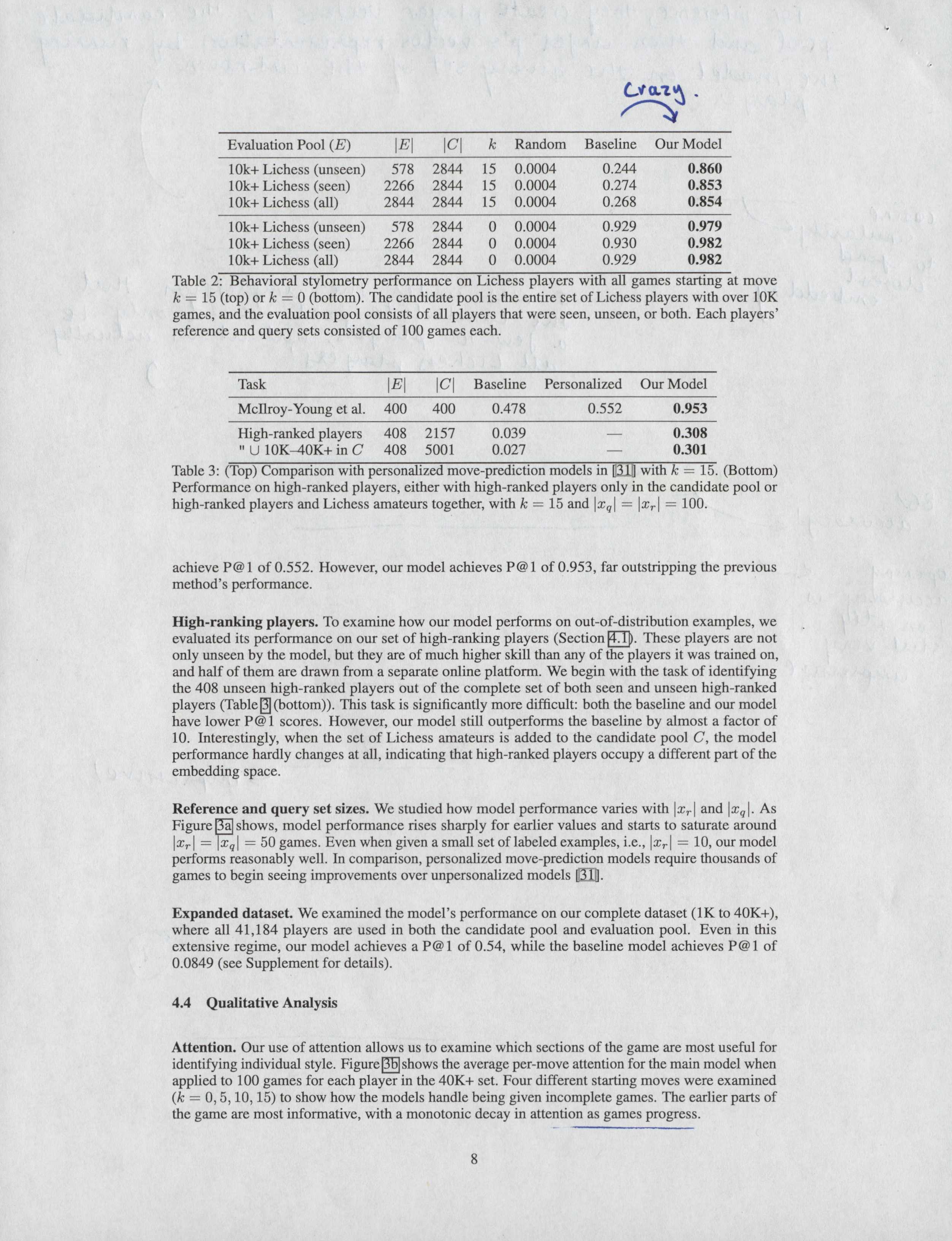
They get a lot LOT of data from Lichess and it is essentially split into seen and unseen sets. The seen dataset is used for the training task, while unseen will be used for testing and evaluation. This prevents any potential overlap in the future.
-
Each set is also split into:
- Training set: games used to train the model
- Reference set: games used for the model do understand who each candidate player is
- Query set: games of unknown players that the model must identify
-
The task of the model is to essentially identify a player by their chess decisions alone. It is provided with a pool of candidate players and about 100 reference games from where it can extract the playing style of candidates. Then, it is provided with query games where it must identify the player from the provided candidate pool and reference games
Annotations









Script
What if you could identify a chess player just by looking at the moves they make? This paper by researchers from the University of Toronto, Microsoft Research, and Cornell University explore the concept of behavioural stylometry – essentially, recognizing a person by looking at their actions alone.
Beyond being really cool and scary, it shows how AI can be used to understand and mimic human decision-making styles. The model works by breaking down the chess game into sequences of moves and analyzing them at multiple levels. It first looks at individual moves, then aggregates these to understand the game as a whole, and finally compiles a profile of the player’s style. Essentially, it is kind of an embedding model for chess player styles.
But if such detailed behavioral analysis can identify a chess player so accurately, what happens when this technology is applied to more sensitive areas? Privacy concerns are real, and the ability to de-anonymize people just from their choices is a frightening prospect