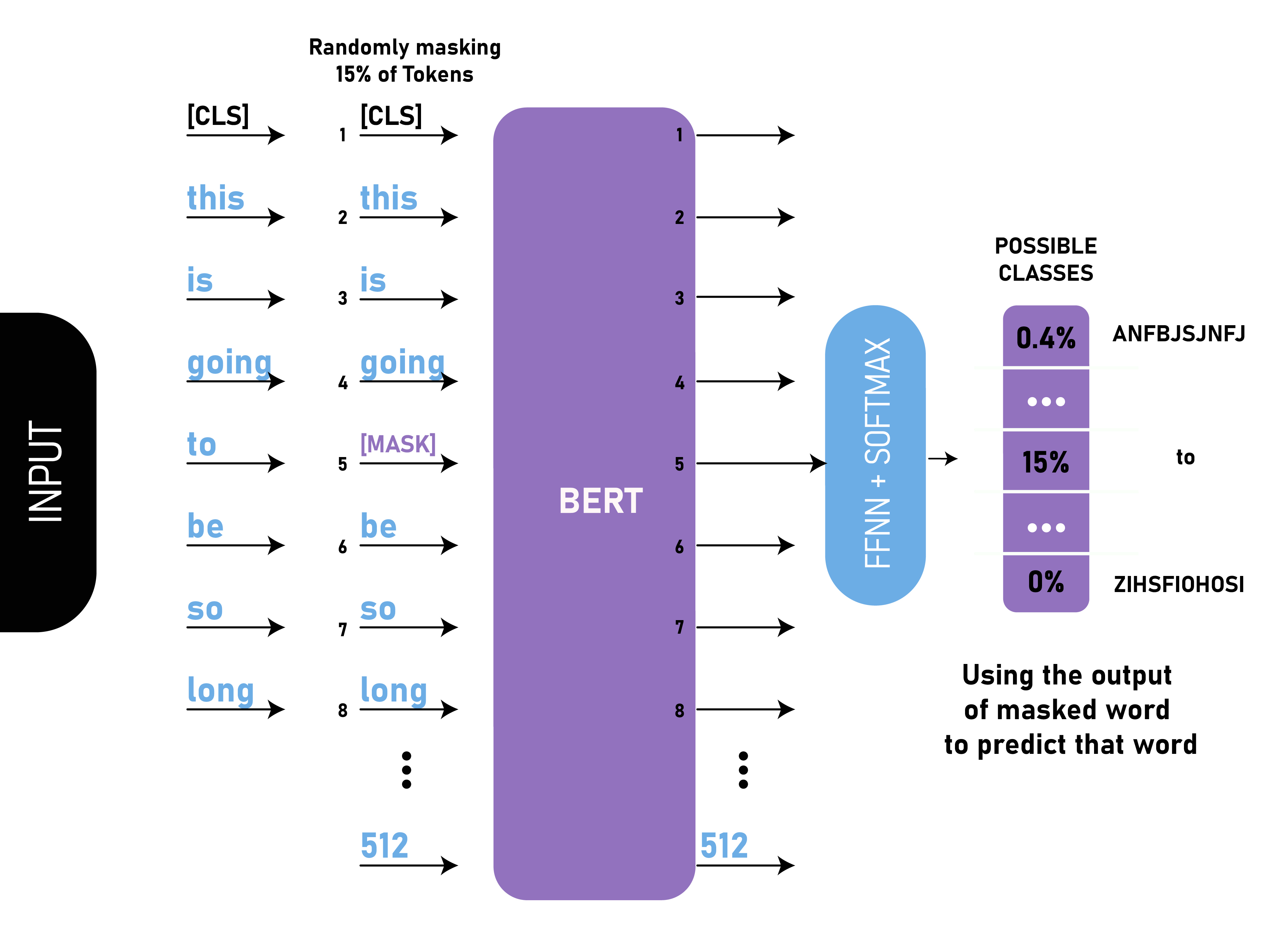
BERT is Google’s language model for Natural Language Processing tasks, which understands the context of words in relation to their surroundings within a sentence. This makes it very effective for tasks like question-answering, text classification, and sentiment analysis.
BERT uses the Transformer architecture, so it processes text and captures the dependencies and relationships between words. BERT also reads text bi-directionally so it can capture the full context surrounding each word. It was trained by randomly masking words in a sentence and then predicting the masked words based on the surrounding context.
Once trained, BERT can be fine-tuned on specific datasets for various NLP tasks. Because of its deep contextual understanding, BERT is used in applications that require nuanced language understanding, such as search engines, chatbots, sentiment analysis, and more.