Semantic search, also known as vector search, enables ranking content based on context relevance. It is at the forefront of the paradigm shift in how we access information as we transition from keyword-based retrieval to a more nuanced, context-based, dialogue-driven search function. Semantic search also players a significant role in Generative AI and LLMs since they are also used to generate content that aligns with user intent and context.
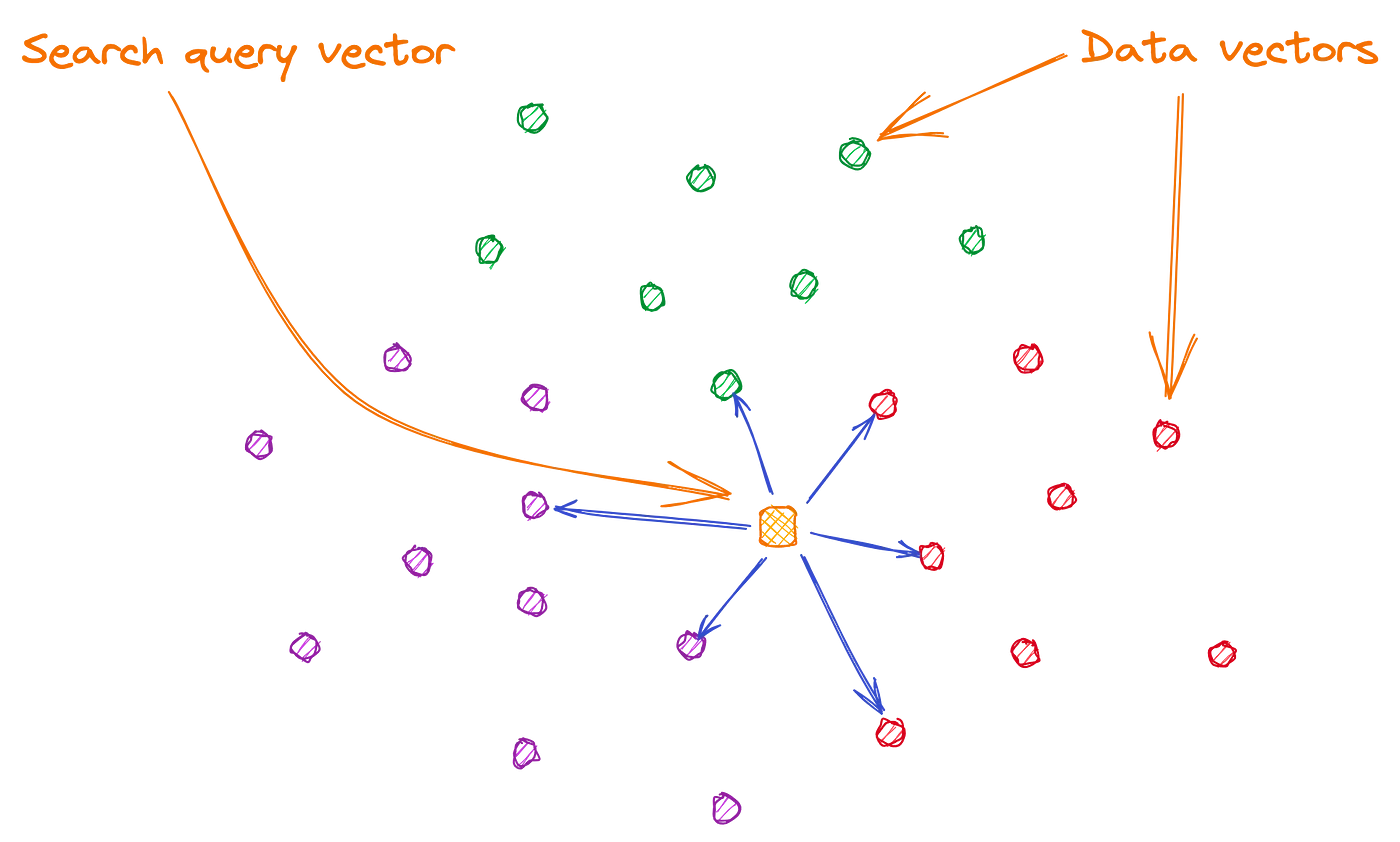
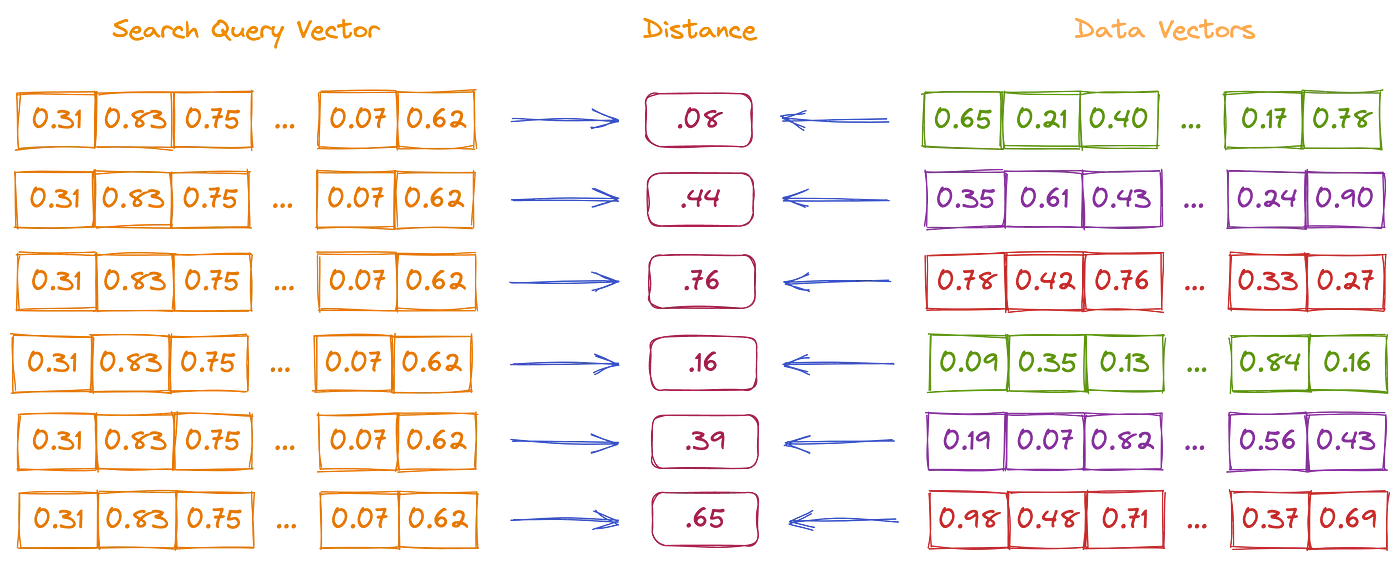
Since embeddings encode details of context and semantics inside vectors, semantic search can encode searchable information into vectors and then compare vectors to determine which are most similar. There are three common similarity metrics used in semantic search:
- Euclidean Distance (L2)
- Cosine Similarity
- Dot Product
Euclidean Distance
Euclidean distance measures the length of the line segment that connects the two vectors in embedding space. The smaller the distance, the more similar they are.

Cosine Similarity
Cosine similarity essentially measures the angle between the two vectors in embedding space. The smaller the angular difference between the vectors, the more similar they are.
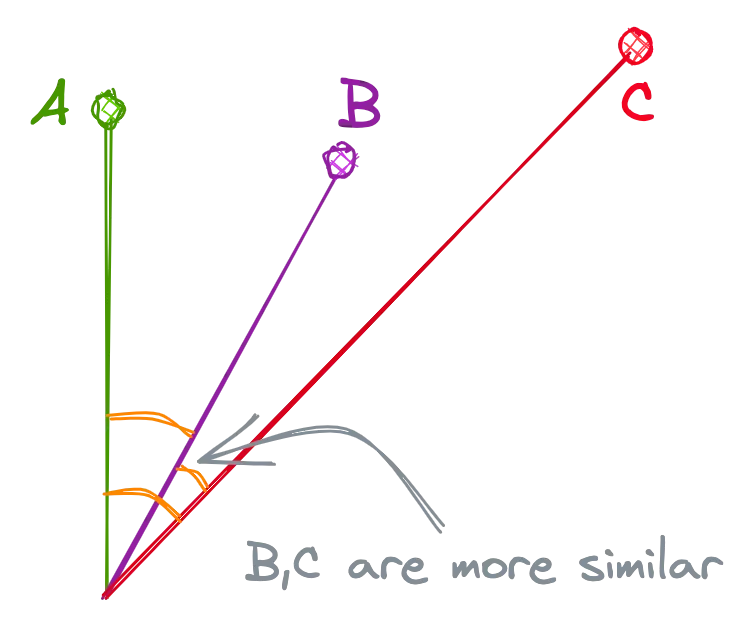
Dot Product
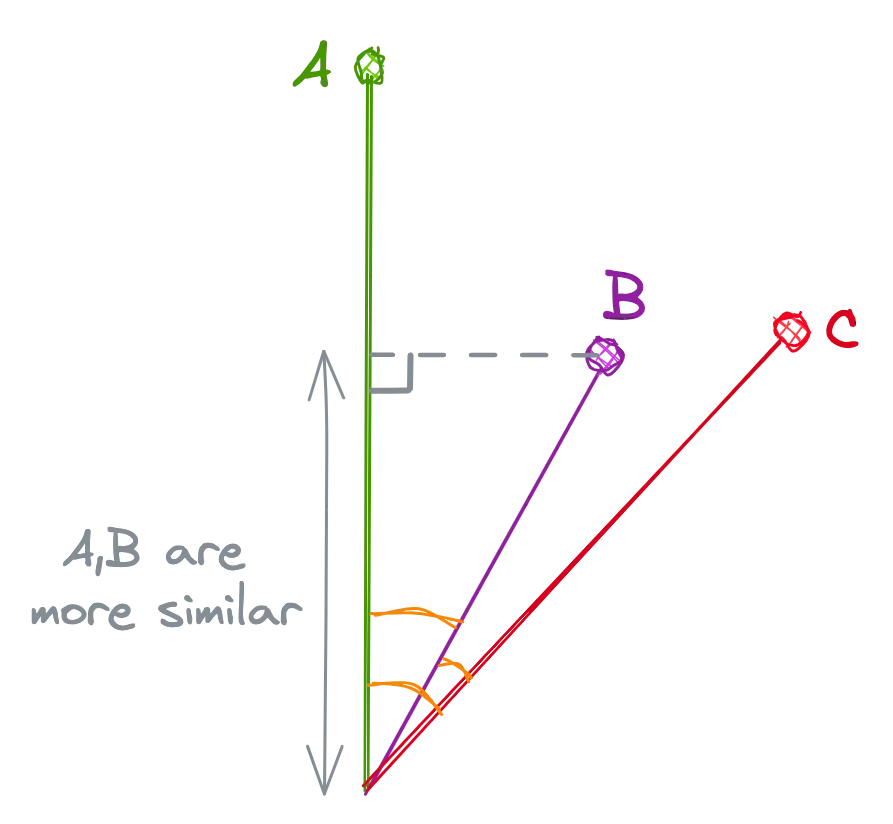
The dot product is the dot multiplication of the 2 vectors, and it is proportional to both the cosine and the lengths of the vectors. In the below example, although the cosine is higher for B and C, the increased length of A makes A and B more similar than B and C.
Unfortunately, the similarity is calculated for each data vector against the query vector, which is unsustainable for large datasets. Some optimizations will need to be made to ensure performant semantic search in large datasets. These optimizations have three main factors:
- Search Quality
- Search Speed
- System Memory Different algorithms and techniques come with different trade-offs
Flat Index (No Optimization)
Calculate the similarity of each data vector against every query vector. This method is only used when accuracy is prioritized over other factors
- High accuracy
- Good until 10k-50k records
- Reduced speed when large amounts of data
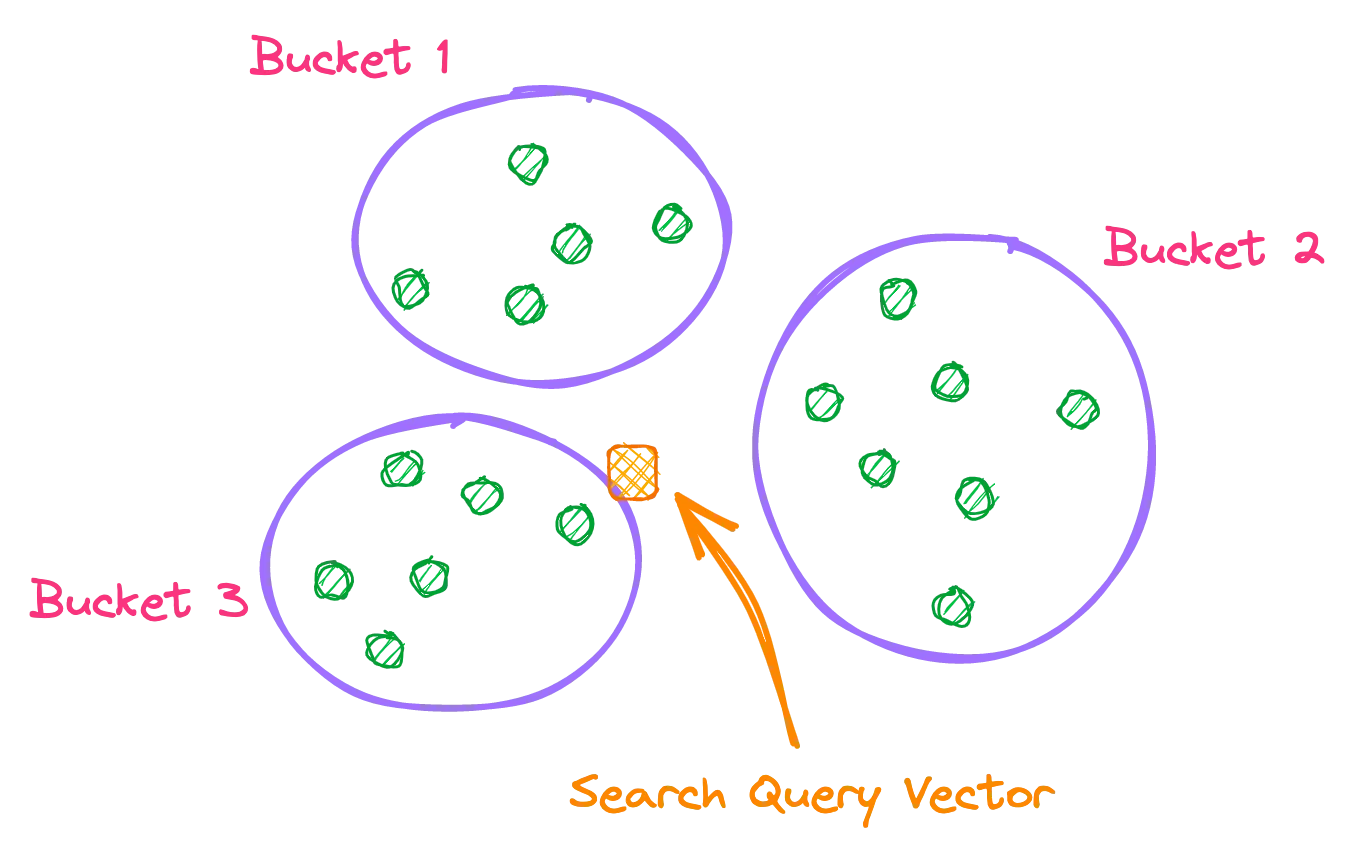
Locality Sensitive Hashing
Data records that are near each other are location in buckets, while data points that are far from each other are in different buckets. The search vector will only be compared against the buckets, and then a specific search is performed within the matched buckets.
- Moderate accuracy
- Lots of buckets are needed for good results
- Leads to extra memory
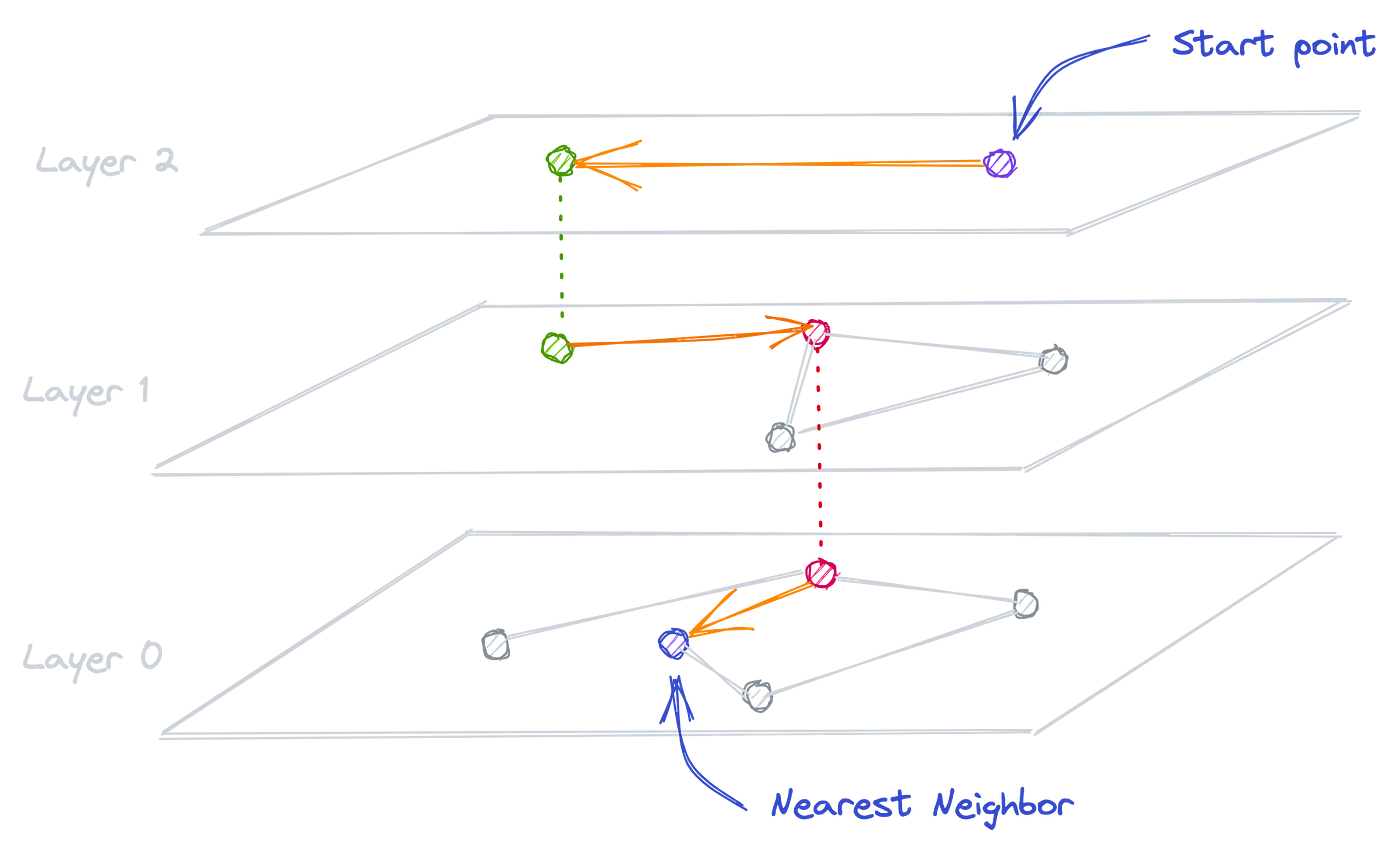
Hierarchical Navigable Small World Graph (HNSW)
Create a multi-layer graph from the data, helping the algorithm quickly find approximate nearest neighbours. HNSW has two different methods: probability skip list, and navigable small world graph.
- Lower accuracy (compared to Flat Index)
- Very fast, and can work with large datasets
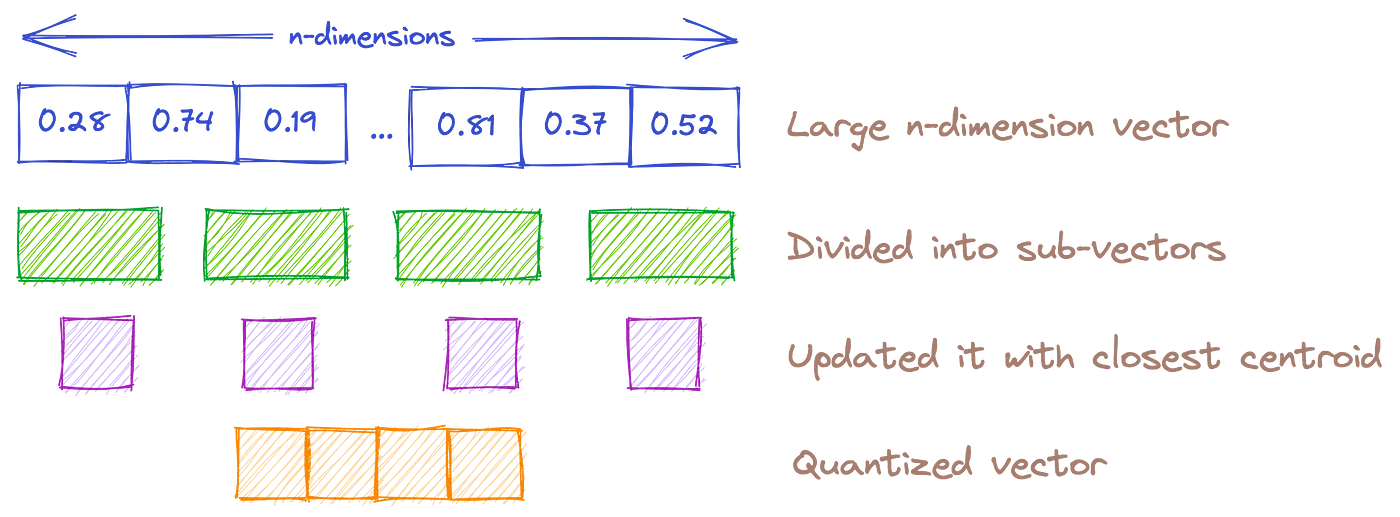
Product Quantizer
Reduce the size of the database by decreasing the precision of the vectors. Essentially, reduce the dimensionality of the vectors.
- Good accuracy (lower than Flat Index)
- Very fast, and can work with large datasets
- Less required memory
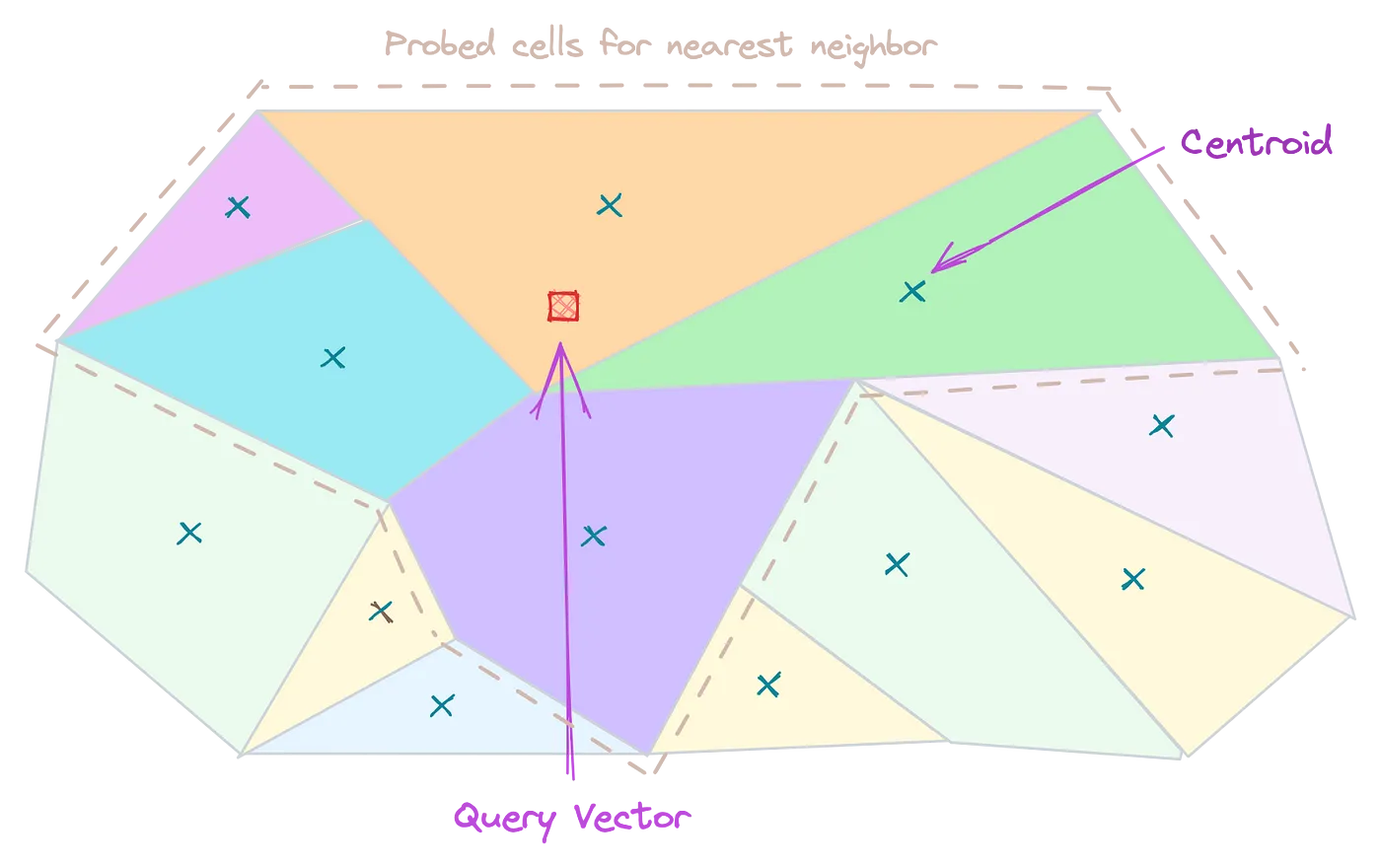
Inverted File Index (IVF)
Partition the data into different cells and assign a centroid for each partition (potentially use k-means). Only compare the vector centroids of each cluster to the search query.
- Good Accuracy (lower than Flat Index)
- Less memory, and average speed