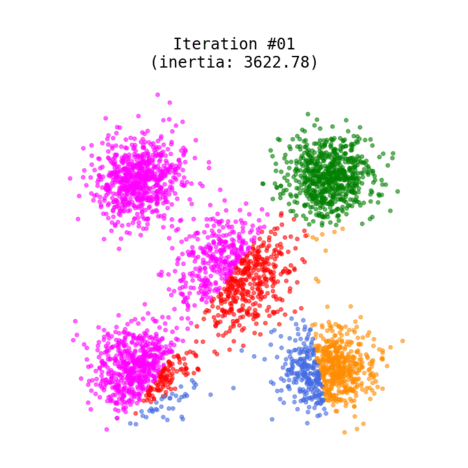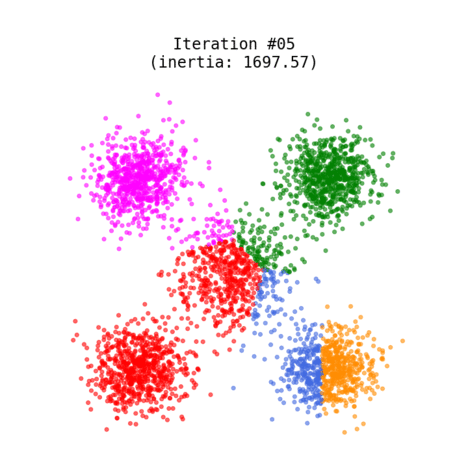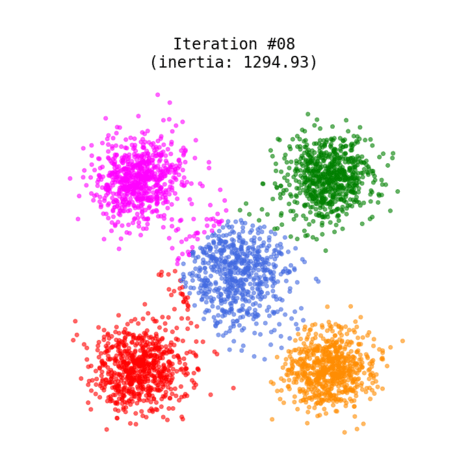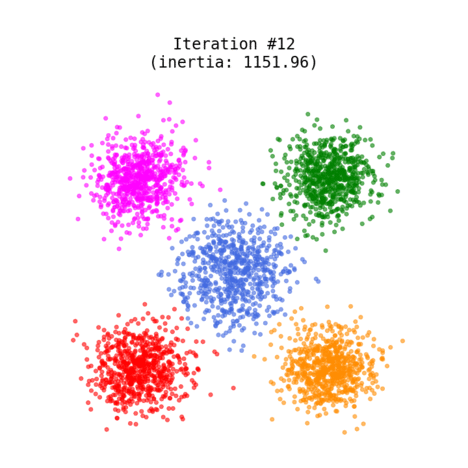
The most popular technique used for grouping data points or objects that are familiar. It can group unsupervised data (no trained model) based on the similarity of the data to each other. It is a partitioning-based algorithm that divides into k non-overlapping subsets (clusters) without any label references to train. It serves to minimize the intra-cluster distances and to maximize the inter-cluster distances.
Algorithm
- Randomly places K markers (called centroids), one for each cluster
- Calculates the distance of each point from the centroid (eg: euclidean distance, manhattan distance)
- Assigns each data point to its closest centroid, creating a cluster
- Recalculates the position of the K centroids
- Repeats steps 2-4 until the centroids no longer move
- Calculate variances and then repeat steps 1-5 using K new randomly placed centroids until N user-defined iterations are complete
- Assign the data to clusters which had the smallest saved variance