CLIP is a multimodal model developed by OpenAI which combines images and text to learn a shared representation of visual and textual information. It is widely used for zero-shot captioning of images.
CLIP was trained using a contrastive learning approach, where it was trained on image-text pairs from the internet. This allowed it to learn which caption matches with which image by optimizing for similarity between correct image-text pairs and pushing apart incorrect pairs.
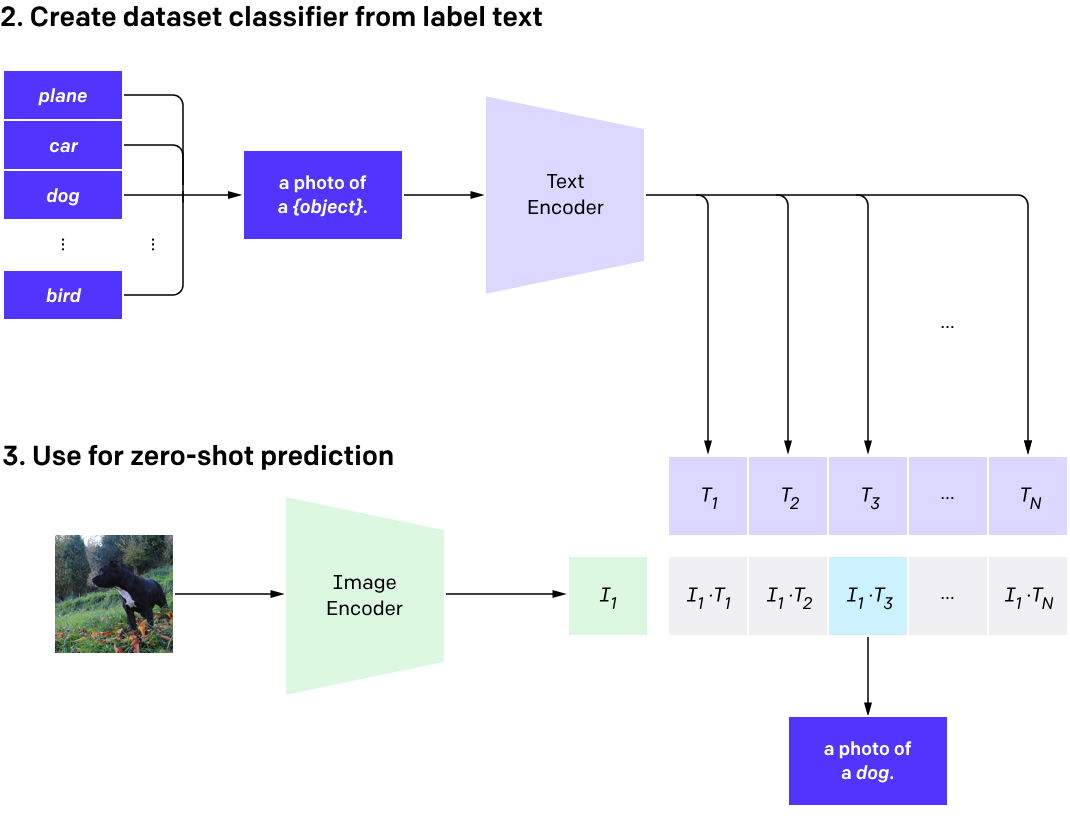
It has two parts: an image encoder (like ResNet or a Vision Transformer) and a text encoder (typically a Transformer). Each encoder transforms its input into a feature vector, which represents the image or text in a high-dimensional space. The model then measures the similarity between these vectors to determine how well they match.
Even without fine-tuning, CLIP is often used for image classification, image search, and image generation guidance. For example, models like DALL-E use CLIP to guide their own image generation. CLIP also features a strong zero-shot learning ability, where it can generalize to new tasks without needing specific task-based training data.
An interesting interpretability finding from OpenAI was the idea of Multimodal Neurons, where they found that certain concepts were stored in single neurons in the model. For example, the same neuron would light up for photos of a spider, photos of spiderman, and photos of text writing spider. This suggests that CLIP semantically understands its inputs, and that a single neuron might be responsible for this phenomenon as well. However, recent Polysemanticity research shows that models might be far more complicated than this.