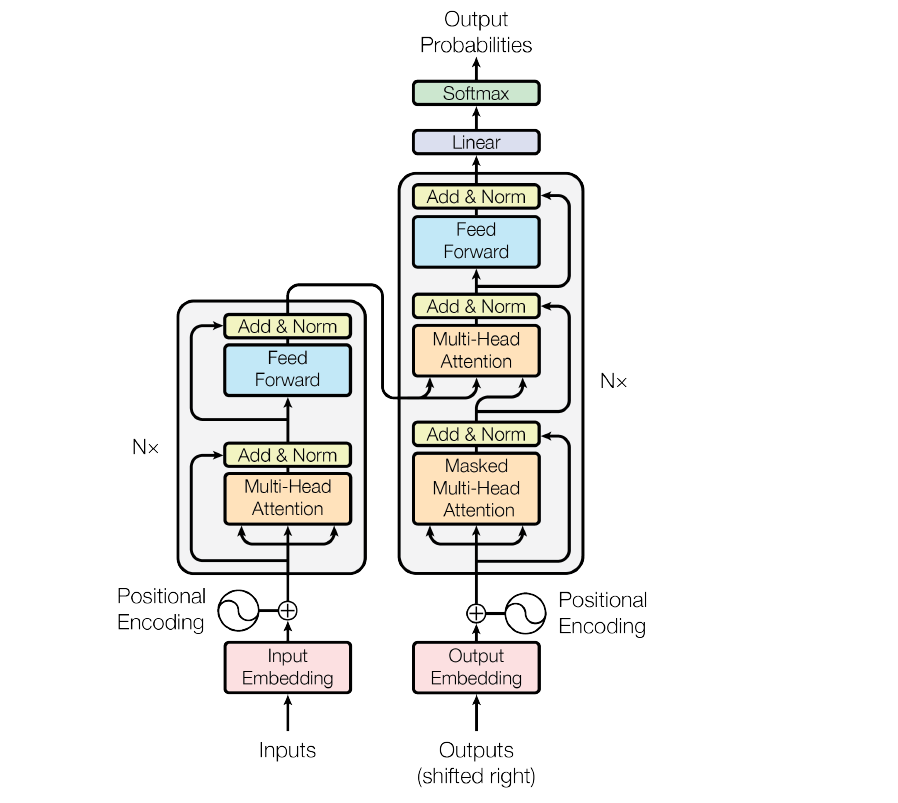
The Attention mechanism is a modern deep learning paradigm introduced in the paper Attention Is All You Need (Vaswani et al. 2017). It introduced the Transformer Architecture, which is the key to the functioning of all modern large language models: GPT, Claude, Llama, and lots more.
The initial goal was to improve Sequence2Sequence Models for neural machine translation, but the authors saw the potential for tasks like question-answering and what is now known as multimodal Generative AI. It has come to replace Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) models.
Functionality
The Attention mechanism essentially allows models to focus on specific parts of input data when making predictions. Similar to other neural network architectures, it does this by assigning weights to different parts of the input data. There are three main parts to the attention mechanism:
- Query (Q): Represents what the model is trying to find or focus on. In a translation task, this would be the current word being translated.
- Key (K): Represents the attributes of all elements in the input sequence; essentially, each element has a key that helps determine the importance for a given query
- Value (V): Contains the information of the input sequence and what the model will use after calculating relevance
First, the model uses dot product multiplication to compute a score for each input element, allowing it to determine its relevance to the query. Then, the scores are passed through a Softmax Activation Function to convert them into probabilities, which are attention weights
Finally, each Value (V) is multiplied by its attention weight, and the sum of these weighted values produce the output.
Types of Attention
There are thee fundamental implementations of the Attention mechanism:
- Self-Attention: Used in Transformers, each word/token attends to all other words, so the model understands contextual relationships
- Cross-Attention: In tasks like translation, cross-attention aligns the source and target sequences, allowing it to focus on relevant words in the source
- Multi-Head Attention: Extends attention by using multiple attention mechanisms in parallel, where each head learns to focus on different aspects of the input