ControlNet is a deep learning diffusion model used to guide diffusion-based image generation models, like Stable Diffusion, by adding more control over the image generation process. Essentially, ControlNet can take an input image or sketch, use its structural or feature details, and direct the model to generate new images which use the specific details for more creative adjustments.
ControlNet builds on regular diffusion models but addresses their inability to follow structural guidance like poses or edges from input images. It adds extra “control” inputs, enabling users to influence generated images more precisely.
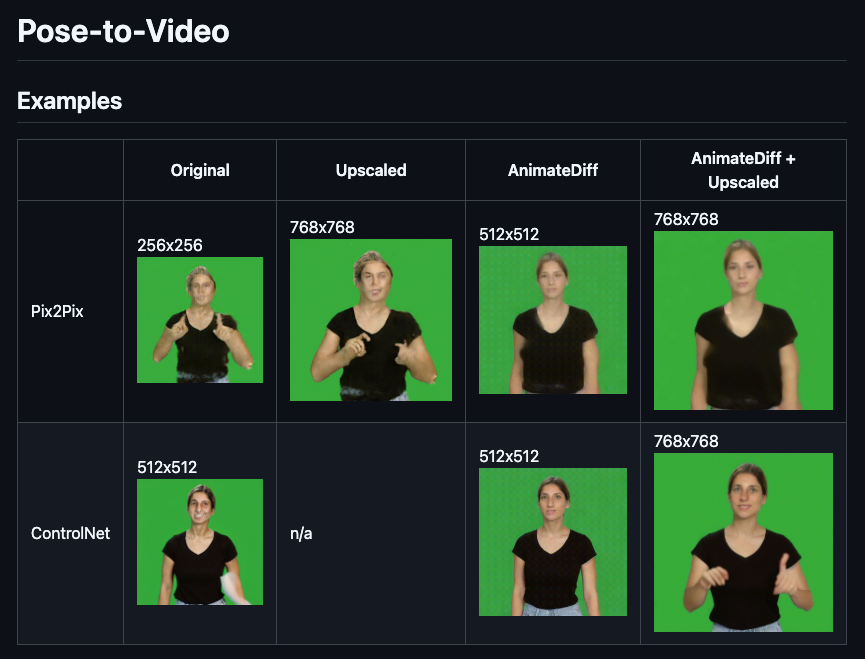
Below is an example of how ControlNet improves video generation and diffusion in sign language production: