Embeddings are numerical representations of values like text, images and audio that are designed to be consumed by machine learning models and Semantic Search algorithms. Ideally, embeddings capture the semantics of inputs by placing semantically similar inputs closer together in the embedding space. With semantic search, embeddings also enable ML models to search for objects based on similarity, semantics or context. Embeddings are also key to the functioning of Large Language Model (LLM).
Since mathematical models cannot interpret information like text, images and audio, embeddings allow us to convert them into vectors. These numerical values represent information in a multi-dimensional space and help models understand the similarities among various items.
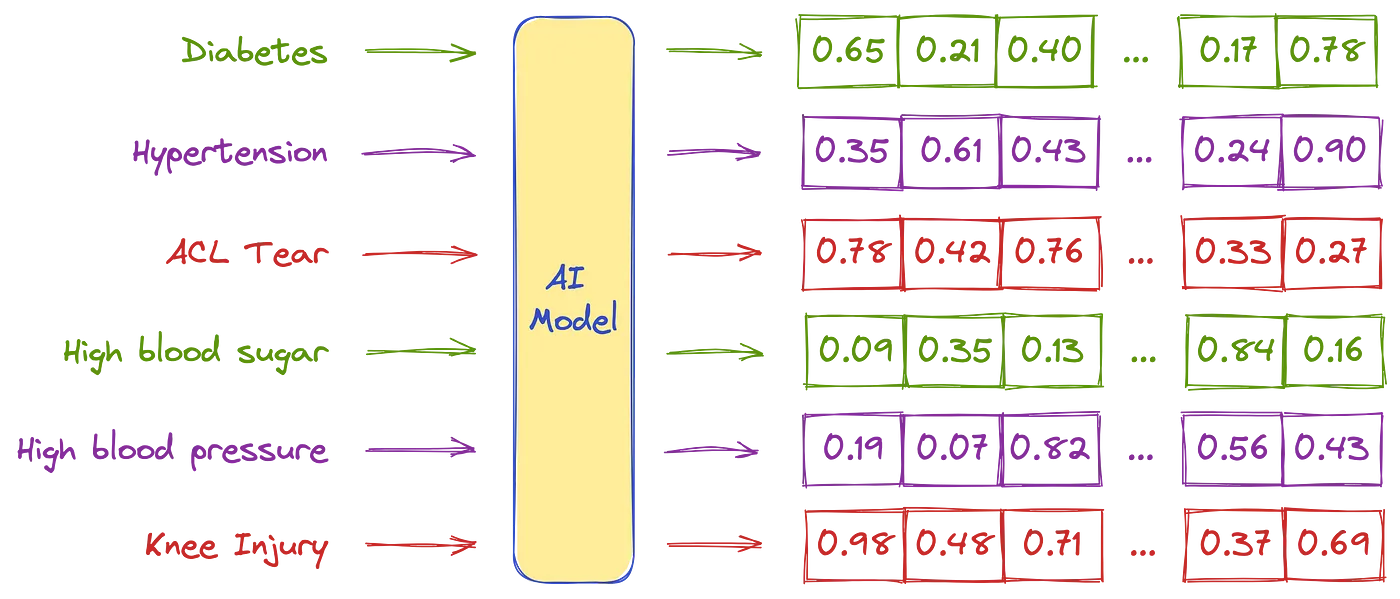
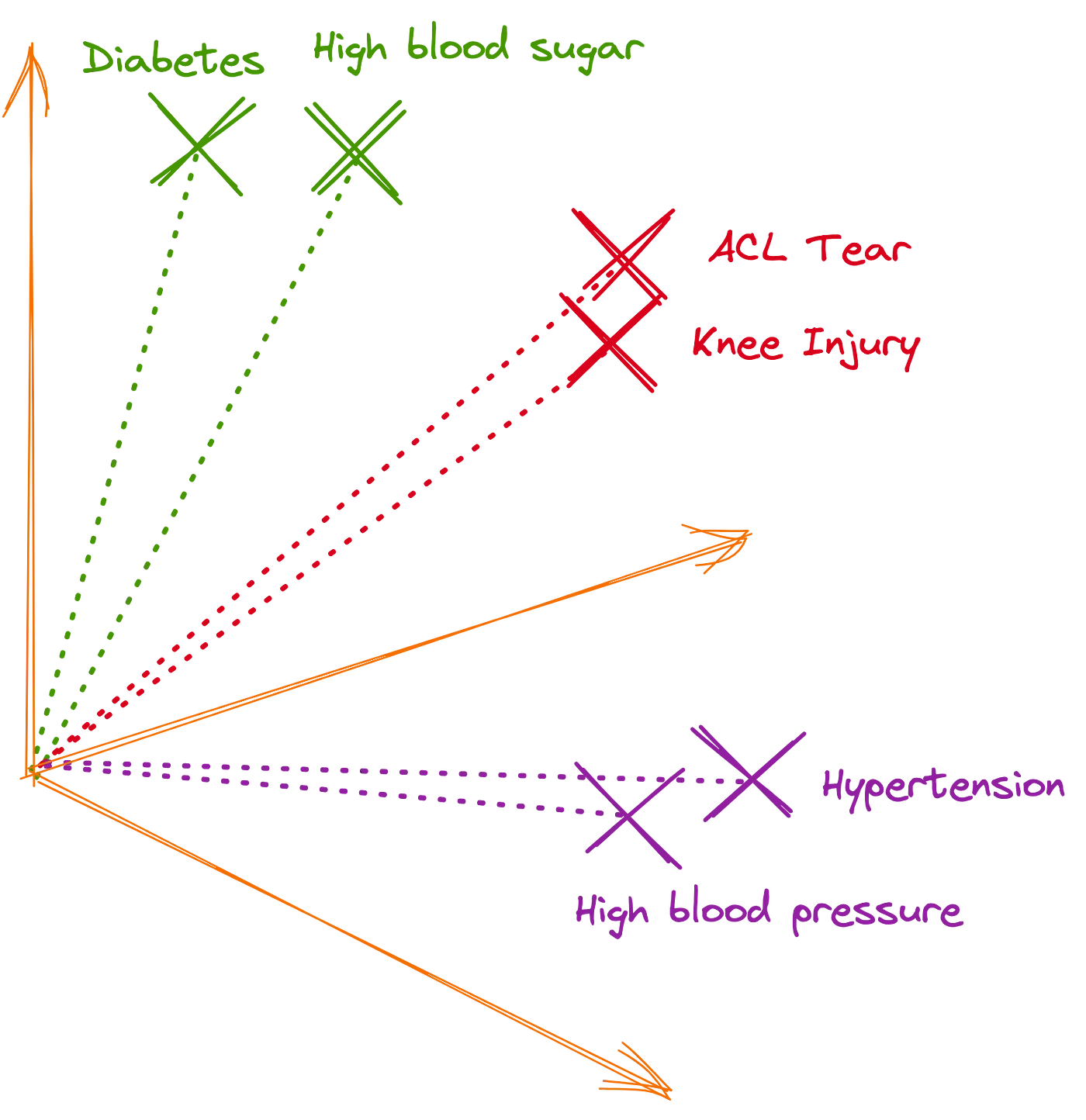
In embedding space, certain dimensions might be associated with certain semantics. For example, one dimension might correspond with age, and larger values in these dimensions tend to correspond with older age. In such an example, the word grandfather might have a high value in this specific dimension, and the word baby might have a low value in the same dimension. When hundreds of dimensions are used, embedding space retains the semantic meaning of words to a strong degree. This also allows semantic search to find contextually similar items.
Sources
- https://aws.amazon.com/what-is/embeddings-in-machine-learning
- https://www.cloudflare.com/learning/ai/what-are-embeddings/
- https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture
- https://medium.com/@sudhiryelikar/understanding-similarity-or-semantic-search-and-vector-databases-5f9a5ba98acb