DBSCAN Clustering is a clustering algorithm which allows unsupervised grouping of data (we don’t train a model) based on the initial similarity of the data. It is considered the most popular technique used for grouping data points or objects that are somewhat familiar. It uses the density of points to define a cluster and does not required the number of clusters to be defined.
Terms
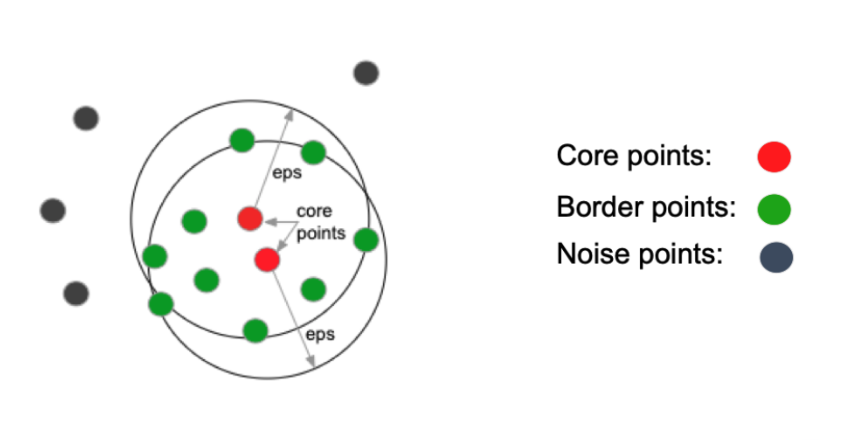
- Epsilon: radius which defines a neighborhood of points around a center point
- Core Point: a point at the center of the cluster
- Minpts: (density threshold) the minimum number of points that must exist inside the epsilon radius from a core point
- Border Point (non-core point): a point that has less than minpts points within the epsilon radius around it, but is within the neighborhood of a core point
- Noise Point (outlier point): a point that is not a core or border point
- Density-reachable: points that are connected through multiple core points
- Density-connected: points that share the same core point that is density-reachable
Algorithm
- Find all core points in the dataset
- Randomly pick a core point and assign it to a cluster
- Extend the cluster by adding surrounding core points that are within the epsilon of another core point
- Once all core points are in clusters, check surrounding non-core points and add them to the cluster if they are within the epsilon of a core point in the cluster
- Repeat the process for all other core point that are not in clusters
- Leftover points are noise points (outliers)