Clustering is the method of grouping entities based on similarities. It is essentially the process of finding similar structures in a set of unlabeled data to make it more understandable and manipulative. It also reveals subgroups in datasets such that every individual cluster has greater homogeneity than the whole dataset. The algorithms extract patterns and inferences from the type of data objects and then makes discrete classes to suitably cluster them. There are various types of clustering:
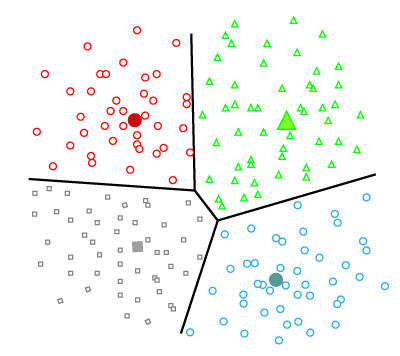
Partitioning Clustering
Uses a predefined number of clusters and then iteratively measures the distance between the clusters and the centroids using distance metrics. For example: K-Means Clustering
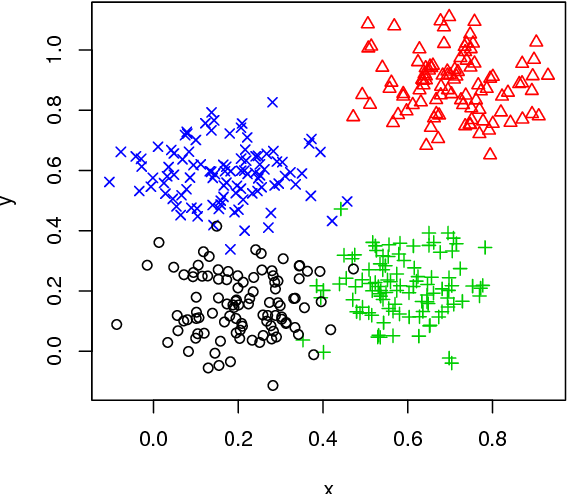
Density-Based Clustering
Data is clustered by regions of high concentrations of data objects bounded by areas of low concentrations of data objects. They consider density ahead of distance. For example: DBSCAN Clustering
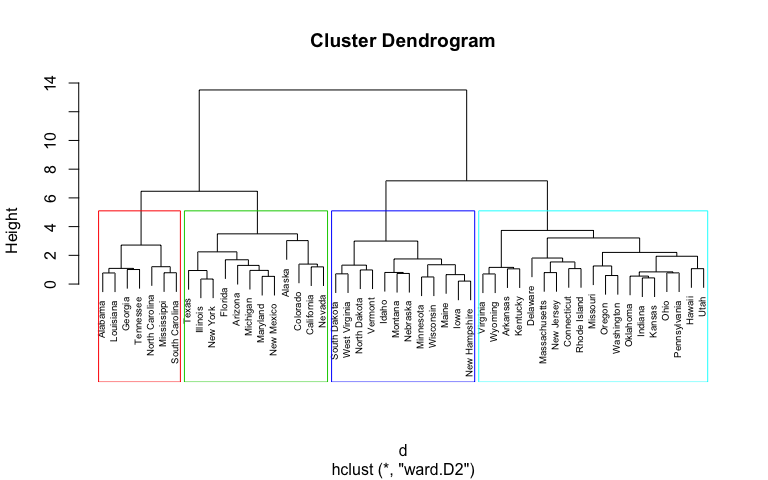
Hierarchical Clustering
Based on the principle that every object is connected to its neighbours depending on their proximity distance. The clusters are represented in hierarchical structures that are separated by a maximum distance required to connect cluster parts.